In a recent demonstration video titled “Hands-on with Gemini: Interacting with multimodal AI,” Google showcased its GPT-4 competitor, Gemini, with high expectations. However, a Bloomberg opinion piece highlights concerns about the video’s accuracy and transparency.
According to Bloomberg, Google admitted that parts of the video were staged, with edits made to accelerate the outputs, as disclosed in the video description. The implied voice interaction between a human user and the AI, touted in the demonstration, was revealed to be non-existent. Instead, the actual demo involved the creation of interactions by “using still image frames from the footage and prompting via text,” rather than responding to real-time drawing or object changes on the table.
The lack of a disclaimer about the actual input method raises questions about the readiness of Gemini, portraying a less impressive capability than the video implies. While Google denies any wrongdoing, referencing a post by Gemini’s co-lead, Oriol Vinyals, stating that “all the user prompts and outputs in the video are real,” critics argue that the tech giant should exercise more sensitivity in its presentations, especially given the increased scrutiny from both the industry and regulatory authorities on AI practices.
Really happy to see the interest around our “Hands-on with Gemini” video. In our developer blog yesterday, we broke down how Gemini was used to create it. https://t.co/50gjMkaVc0
We gave Gemini sequences of different modalities — image and text in this case — and had it respond… pic.twitter.com/Beba5M5dHP
Google has announced a substantial update for Bard, its generative AI chatbot and competitor to ChatGPT. The company claims that this update will significantly boost Bard’s capabilities by integrating Gemini, Google’s latest and most advanced AI model. The incorporation of Gemini is expected to enhance Bard’s reasoning, planning, understanding, and other functionalities.
Gemini is available in three sizes – Ultra, Pro, and Nano – making it adaptable for deployment on a range of devices, from mobile phones to data centers.
The rollout of Gemini to Bard will occur in two phases. Initially, Bard will receive an upgrade with a specially tuned version of Gemini Pro. In the following year, Google plans to introduce Bard Advanced, offering users access to the top AI model, starting with Gemini Ultra.
The version of Bard featuring Gemini Pro will initially be available in English across more than 170 countries and territories globally, with additional languages and countries, including the EU and U.K., to follow soon.
Before its public launch, Gemini Pro underwent industry-standard benchmark testing. Google reports that Gemini outperformed GPT-3.5 in six out of eight benchmarks, including significant multitask language understanding tasks and grade school math reasoning. However, it’s worth noting that GPT-3.5 is over a year old, leading some to view this as more of a catch-up move rather than an outright improvement, as highlighted by TechCrunch’s Kyle Wiggers.
The enhancements brought by Gemini are expected to make Bard more proficient in tasks such as content understanding and summarization, reasoning, brainstorming, writing, and planning.
Sissie Hsiao, VP and GM of Assistant and Bard at Google, described this upgrade as the “biggest single quality improvement of Bard since we’ve launched.”
Gemini Pro will initially power text-based prompts in Bard, with plans to expand to multimodal support (texts, images, or other modalities) in the coming months.
In 2024, Bard Advanced will debut, offering a new experience powered by Gemini’s most capable model, known as Gemini Ultra. This model can comprehend and act on various types of information, including text, images, audio, video, and code, with multimodal reasoning capabilities. Gemini Ultra can also understand, explain, and generate high-quality code in popular programming languages, according to Google.
Google will launch a trusted tester program for Bard Advanced before a broader release early next year. Additionally, the company will subject Bard Advanced to additional safety checks before its official launch.
This update follows several improvements to Bard over the past eight months, including features like answering questions about YouTube videos and integrating with various Google apps and services. With Gemini, Google aims to bring users “the best AI collaborator in the world,” acknowledging that Bard is not quite there yet.
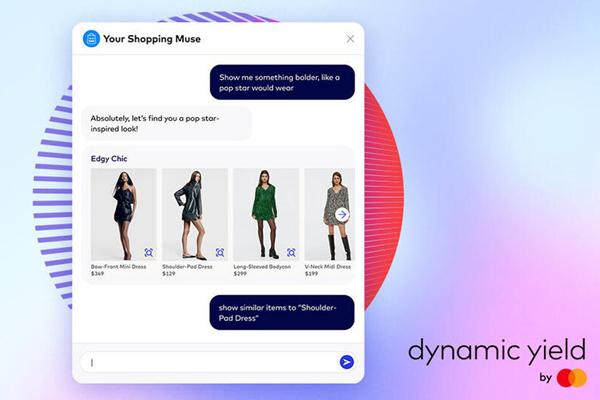
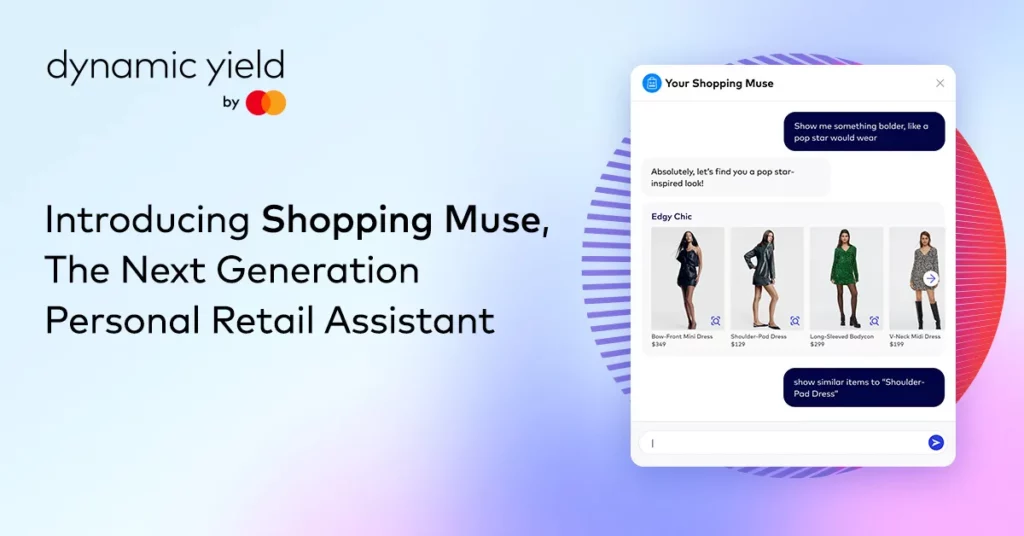
Mastercard has announced the launch of its innovative generative AI shopping tool, “Shopping Muse,” aiming to revolutionize the way users explore and discover products in digital catalogs. Powered by Dynamic Yield, a personalization company acquired by Mastercard in April 2022, Shopping Muse utilizes advanced algorithms to provide personalized product recommendations based on users’ colloquial language and modern trends.
The tool enables users to ask questions in natural language, such as “What should I wear for a summer wedding?” or “Can you recommend pieces for a minimalist capsule wardrobe?” Shopping Muse analyzes the context of the user’s shopping experience, direct questions, and conversation content to deliver tailored suggestions. It leverages data from the retailer’s product catalog, on-site behavior, real-time preferences, and known consumer preferences.
Shopping Muse goes beyond text-based queries, employing integrated advanced image recognition tools. Retailers can recommend relevant products based on visual similarities, even in cases where users struggle to describe what they are looking for. Although initially focused on fashion, Mastercard anticipates extending the technology to other categories like furniture and grocery.
Ori Bauer, CEO of Dynamic Yield by Mastercard, emphasized the significance of AI-driven innovation in providing immersive and tailored online shopping experiences. He stated, “By harnessing the power of generative AI in Shopping Muse, we’re meeting the consumer’s standards and making shopping smarter and more seamless than ever.”
Highlighting the need for retailers to embrace technology, Mastercard emphasized that over one in four retailers already use generative AI solutions, with an additional 13% planning to adopt them in the next year. The company urged adaptation to changing demands and noted that personalization through AI-driven technology is crucial for meeting consumer expectations.
As part of a broader trend in AI-powered shopping tools, Google now enables users to receive AI-generated gift recommendations on Search, while Microsoft’s Bing automatically generates buying guides for queries like “college supplies.” Industry experts, as reflected in a recent Gartner report, predict that 80% of customer service and support organizations will integrate generative AI technology in some form by 2025. The release of Shopping Muse signifies a significant addition to the evolving landscape of AI-driven shopping solutions.
In the not-so-distant past, just a year ago in November, the world of machine learning was focused on constructing models for specific tasks such as loan approvals and fraud protection. Fast forward to today, the landscape has shifted with the emergence of generalized Large Language Models (LLMs). However, the era of task-based models, described by Amazon CTO Werner Vogels as “good old-fashioned AI,” is far from over and continues to thrive in the enterprise.
Task-based models, the foundation of AI in the corporate world before LLMs, remain a crucial component. Atul Deo, general manager of Amazon Bedrock, a product introduced to connect with large language models via APIs, emphasizes that task models haven’t vanished; instead, they’ve become an additional tool in the AI toolkit.
In contrast to LLMs, task models are tailored for specific functions, whereas LLMs exhibit versatility beyond the predefined model boundaries. Jon Turow, a partner at investment firm Madrona and former AWS executive, notes the ongoing discourse about the capabilities of LLMs, such as reasoning and out-of-domain robustness. While acknowledging their potential, Turow highlights the enduring relevance of task-specific models due to their efficiency, speed, cost-effectiveness, and performance in specialized tasks.
Despite the allure of all-encompassing models, the practicality of task models remains undeniable. Deo argues that having numerous separately trained machine learning models within a company is inefficient, making a compelling case for the reusability benefits offered by large language models.
For Amazon, SageMaker remains a pivotal product within its machine learning operations platform, catering specifically to data scientists. SageMaker, with tens of thousands of customers building millions of models, continues to be indispensable. Even with the current dominance of LLMs, the established technology preceding them remains relevant, as evidenced by recent upgrades to SageMaker geared toward managing large language models.
In the pre-LLM era, task models were the sole option, prompting companies to assemble teams of data scientists for model development. Despite the shift towards tools aimed at developers, the role of data scientists remains crucial. Turow emphasizes that data scientists will continue to critically evaluate data, providing insights into the relationship between AI and data within large enterprises.
The coexistence of task models and large language models is expected to persist, acknowledging that sometimes bigger is better, while at other times, it’s not. The key lies in understanding the unique strengths and applications of each approach in the evolving landscape of artificial intelligence.
In a surprising turn of events, ChatGPT, OpenAI’s groundbreaking chatbot, celebrates its first birthday amid a year of upheavals and triumphs. The user-friendly generative AI technology managed to captivate the world, breathing new life into Silicon Valley and sparking an AI arms race.
Unveiling the AI Revolution
A year since its public release, ChatGPT continues to be a driving force behind the ongoing AI revolution. Tech giants invest billions, nations hoard essential chips, and the promises and challenges of generative AI echo through boardrooms and homes worldwide.
Pandora’s Box: Navigating the Impact
ChatGPT’s impact on society unfolds with a mix of excitement and challenges. Schools grapple with integrating the technology into education, artists face disruption, and the labor market experiences shifts, both positive and negative. As AI’s long-prophesied impacts emerge, society collectively navigates the implications of an open Pandora’s box.
Imagining a New Equitable Future
The future of generative AI sparks debates about its impact on society’s equity. As jobs shift from human to AI hands, questions arise about societal adaptation. The transition poses challenges, urging the public to pressure policymakers for creative solutions, such as taxing AI companies or experimenting with universal basic income.
OpenAI’s Rollercoaster Ride
OpenAI, the creator of ChatGPT, faces internal strife, with CEO Sam Altman ousted and reinstated within a span of five days. The turmoil casts a shadow on the organization’s mission of ensuring AI benefits humanity, raising questions about its ability to keep itself together while navigating the transformative potential of AI.
In a significant move into the realm of AI image generation, Amazon has introduced its latest innovation, the Titan Image Generator, a text-to-image AI model. Unveiled at the AWS re:Invent conference, this advanced tool is designed to produce “realistic, studio-quality images” with built-in safeguards against toxicity and bias. Unlike standalone applications or websites, Titan serves as a versatile tool for developers, enabling them to construct their image generators using the underlying model, contingent on access to Amazon Bedrock.
During his keynote address, Swami Sivasubramanian, AWS Vice President of Database, Analytics, and Machine Learning, showcased the Titan Image Generator’s capabilities, emphasizing its proficiency not only in generating images from natural language prompts but also in seamlessly altering backgrounds. This marks a departure from the consumer-oriented focus of existing image generators like OpenAI’s DALL-E, targeting a more enterprise-centric audience.
All images generated by Titan Image Generator will automatically carry invisible watermarks, as part of voluntary commitments made by Amazon to the White House in July. Vasi Philomin, AWS Vice President for Generative AI, explained that this watermarking strategy was devised to distinctly label AI-created images without affecting their visual integrity, latency, or susceptibility to cropping or compression.
However, the detection of the invisible watermark poses a challenge, addressed by Amazon through the creation of an API. Users can connect to this API to verify the image’s provenance, adhering to the intentional design of Titan as a model rather than a finished product. Developers utilizing Titan Image Generator have the flexibility to determine how they convey this information to end-users.
The incorporation of invisible watermarks aligns with the Biden administration’s executive order on AI, emphasizing the identification of AI-generated content. Notably, companies like Microsoft and Adobe have adopted systems such as the Content Credentials system developed by the Coalition for Content Provenance and Authenticity (C2PA). Adobe goes a step further by introducing an icon to signify content credentials in both image and video content.
In addition to Titan Image Generator, Amazon has announced the general availability of other Titan models, including Titan Text Lite—a smaller model suitable for lightweight text generation tasks such as copywriting—and Text Express, designed for more extensive applications like conversational chat apps.
Amazon further extends copyright indemnity to customers utilizing its Titan foundation models, encompassing text-to-image functionalities. Legal coverage is also offered to users of any Amazon-created AI application, even if the application employs a different foundation model sourced from Amazon’s Bedrock AI model repository, which includes models like Meta’s Llama 2 or Anthropic’s Claude 2. Prominent applications under this umbrella include AWS HealthScribe, CodeWhisperer, Amazon Personalize, Amazon Lex, and Amazon Connect Contact Lens.